




在PayPal最后的日子里交接工作的机会,我终于有空隙回过头来审视我一年前写的脚本应用。说起来也挺扯,这几千行代码居然至今还是我加入PP以来写的十万行代码里我自认为最优雅的。
既然他也经历了一年多的线上考验,被十多号人的oncall团队用起来了,感觉还是挺值得分享一下我对它的二次思考。因为设计和实现是我一个人全包的且在下班时间做的,不存在版权问题,也仅此表达我对PP的纪念。
我做对了什么
痛点与曝光
从痛点出发设计,毕竟这也是曝光的时候领导最在乎的。有有价值的出发点再动手。曝光就是开分享会、画PPT。
任务拆解
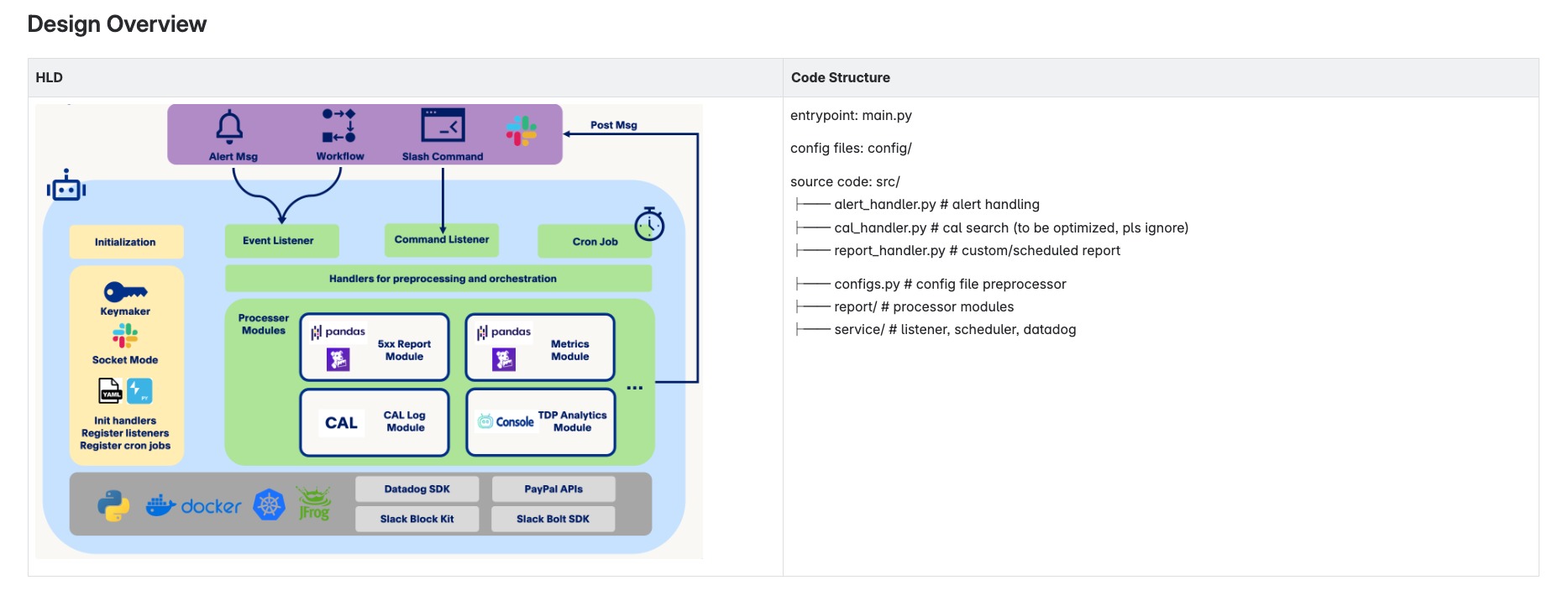
虽然就我一个人做,但是我仿照所有项目的开发流程对整个工具的执行进行了细致到可执行的任务划分。比如我要去调研已有的类似项目、去玩一玩slack app快速开始、用postman测试下游的API确保我能调通,申请下游token。一个看似简单的应用最小可用就需要十个左右的小任务。
代码层面也是类似的,拆解成初始化、运行时、infra相关内容。当然一般infra都是在模版的基础上修改的,比如dockerfile & k8s。
代码复用
重复的代码特别难维护,一改就要改所有。杜绝一切可能得重复逻辑。我的脚本支持push & pull式调用。push – 定时任务做的日报、双周报,推送一些关键的性能和业务指标;pull – 监听报警消息或者命令行交互,实时回复。
殊途同归,请求的内容都是有重叠的。把内容分成最小可复用单元,加一个编排层,将不同的请求编排成可复用单元的调用,然后并行执行返回结果。好处是抽象效果更好且可复用单元可读性高很多。
异常捕捉
我一开始为核心代码加上了异常捕捉。然后写了一个文档,含所有用途的测试用例,包含正常和异常输入。测试过程中缝缝补补把所有可能发生异常的地方都覆盖了,确保python程序不会因为任何异常输入而退出。是的,我遇到过因为ArgumentError, SystemExit而直接程序中断的情况,主要出现在CLI体验的情况。
依赖版本写死
requirements.txt里一定要定义好版本,比如aiohttp=3.9.5。没有版本号基本都会去拉最新的版本,不是所有的库都是版本向后兼容的!
我最开始上线的几个月就有几个lib没写版本,啥事没有。但是半年过后出现了个奇葩的情况,本地写的代码测试是过的,但是推到master上线打的包部署后一直挂。
原因是本地conda list版本和打的包日志里的对不上,conda环境第一次运行就定死了,但是打包每次都拿最新的依赖。某些依赖在半年内发布了大版本,导致了SDK向后不兼容。
配置文件驱动
与逻辑可拆分的配置项写成配置文件。一方面,后续参数调整只需要改配置文件,不涉及代码修改,流程更短。另一方面,逻辑和配置分离容易做到多租户的结构,不同的团队可以通过引入不同的配置文件来实现定制化
限流
大部分API都是要限流的,特别是那种限制个位数并发请求的API要特别注意。可以用一个简单的令牌桶解决
class TokenBucket:
def __init__(self, rate, burst):
self._rate = rate
self._burst = burst
self._tokens = burst
self._last_tick = time.monotonic()
self._lock = Lock()
async def consume(self, tokens):
if tokens > self._burst:
raise BotException(f"Cannot consume more than {self._burst} tokens at the same time")
async with self._lock:
while tokens > self._tokens:
now = time.monotonic()
elapsed = now - self._last_tick
# compute available tokens
self._tokens = min(self._burst, self._tokens + elapsed * self._rate)
self._last_tick = now
# sleep when token is not enough
if tokens > self._tokens:
await asyncio.sleep((tokens - self._tokens) / self._rate)
self._tokens -= tokens
GPT协同编程
都这个时代了,不会还有人在完全手写吧
我做错了什么
一个人写
一个人的力量是有限的,团队可以走得更远。
惯性手动测试
排斥写测试人之常情,做最小版本先把测试放一边可以理解。但是一直拖着不写,迭代的时候还是蛮怂的怕出错,导致实际检查的成本更高。回头来看应该在MVP出来且没有大改之后立马补全测试
缺少AI卖点
AI红利时代,资本或者领导都更愿意听到AI的创意。隔壁团队同一时间用RAG做的AI Bot用起来完全是拉一坨大的,但是曝光度是我的十倍不只。
配置文件膨胀
功能的增加带来配置文件越来越长,其实部分配置项是有机会缩减的,比如根据依赖关系推导或者查询API,冗长的配置文件让人看起来不好上手
开箱即用没做到极致
部分功能有一些前置依赖,需要外部的工作量。有外部团队对我的脚本感兴趣,但是知道需要前置依赖(虽然很简单)后没有采纳。
完全无痛的方案才是大家想要的。就像infra跟我说要升级需要各个团队自己提pr改代码一样,我们很多团队能拖几个月到DDL才改。相反如果他们是透明的更新,最多提交一个工单,没有团队会说不。
一些想法
一份赤裸裸的基本没啥测试类的代码竟然能做到一年内没故障,所有的pull请求秒回,所有的push都准时准点发送,可用率之高说实话让我自己都吃惊。
虽然业务上我们要求99.999%稳定性可用性,各种兜底补偿措施。但是在脚本领域,代码高质量+python libs稳定版本+合格的鸡架已经足以靠谱。
评论区